Overview
The Extract pipeline is the simplest and most common way to use Pulse. Upload a document and get back clean, layout-aware markdown along with extracted tables, figures, bounding boxes, and optional chunks. This is the starting point for every other pipeline — Extract → Schema and Extract → Split → Schema both build on top of this step.When to Use
- RAG ingestion — feed clean markdown into a vector database
- Search indexing — convert documents to searchable text
- Content migration — pull content out of PDFs into your CMS
- Table extraction — grab structured tables from financial reports, invoices, or spreadsheets
- General-purpose parsing — convert any supported file type to machine-readable text
Supported File Types
Pulse handles a wide range of document formats out of the box:| Category | Extensions |
|---|---|
.pdf — text-based, scanned/image-based, mixed, multi-page | |
| Images | .jpg, .jpeg, .png — scans, photos, screenshots |
| Office | .docx, .pptx, .xlsx — Word, PowerPoint, Excel |
| Web | .html, .htm — saved web pages, HTML emails |
For the full breakdown including processing tips per format, see Supported File Types.
How to Use in the Playground
Drag and drop a file or paste a URL into the upload area. You can also upload multiple documents at once for batch processing.
1-5, 3,7,12)For guidance on when to enable footnotes, spreadsheet options, word-level boxes, or chunking, see Processing Parameters.
The extraction runs (synchronously or asynchronously depending on document size). Progress is shown in the pipeline tabs.
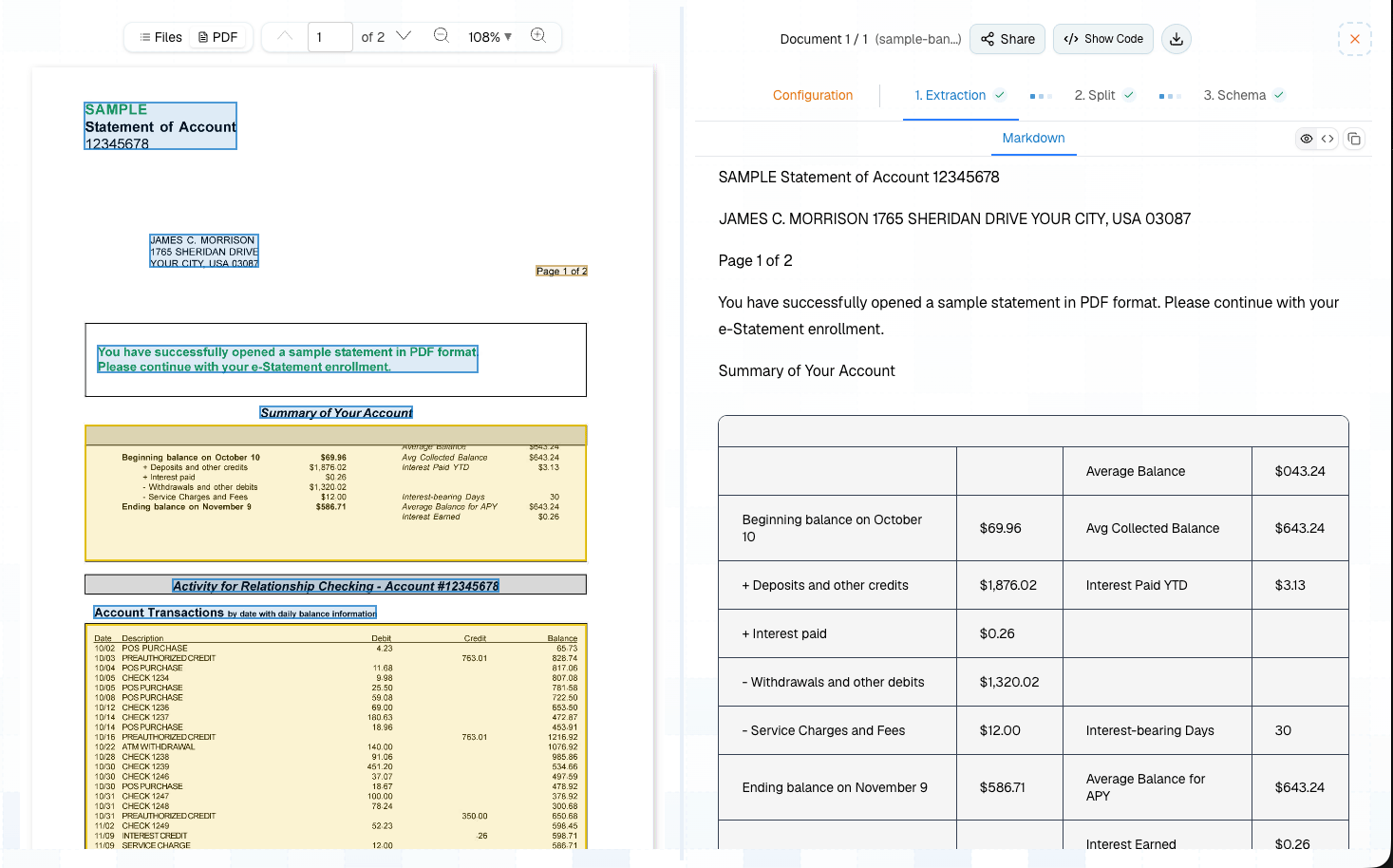
What You Get Back
| Field | Description |
|---|---|
markdown | Full document text with layout-aware markdown formatting |
extensions.alt_outputs.html | HTML output (if extensions.alt_outputs.return_html was enabled) |
extensions.chunking | Chunk data (if extensions.chunking was configured) |
bounding_boxes | Coordinates for every text block, table, and figure |
extraction_id | Saved extraction ID — use this for subsequent /split or /schema calls |
extraction_url | Presigned URL to the stored extraction result |
page_count | Number of pages processed |
API Usage
- Python
- TypeScript
- curl
After Extraction
Once you have yourextraction_id, you can:
Add Schema
Extract structured data fields with a JSON Schema
Split & Schema
Divide into sections and extract per-section structured data
Tables
Extract structured tables with span detection and cross-page merging
Related
Extract API Reference
Full API documentation for the
/extract endpointSupported File Types
Detailed breakdown of every supported format